
Technology 1: AI/Machine Learning
Session: Technology 1: AI/Machine Learning
 photo")
Emma Holmes, MD (she/her/hers)
Assistant Professor
The Mount Sinai Kravis Children's Hospital
New York, New York, United States
 Comparison of accuracy, reason for inaccuracy, and proportion of non-specific diagnoses between the physician and GPT-4o provided diagnoses. Diagnoses were noted for non-specificity if more specific diagnosis was available, and only considered inaccurate if lack of specificity interfered with ability to discern what condition the diagnosis was referring to.
Comparison of accuracy, reason for inaccuracy, and proportion of non-specific diagnoses between the physician and GPT-4o provided diagnoses. Diagnoses were noted for non-specificity if more specific diagnosis was available, and only considered inaccurate if lack of specificity interfered with ability to discern what condition the diagnosis was referring to. 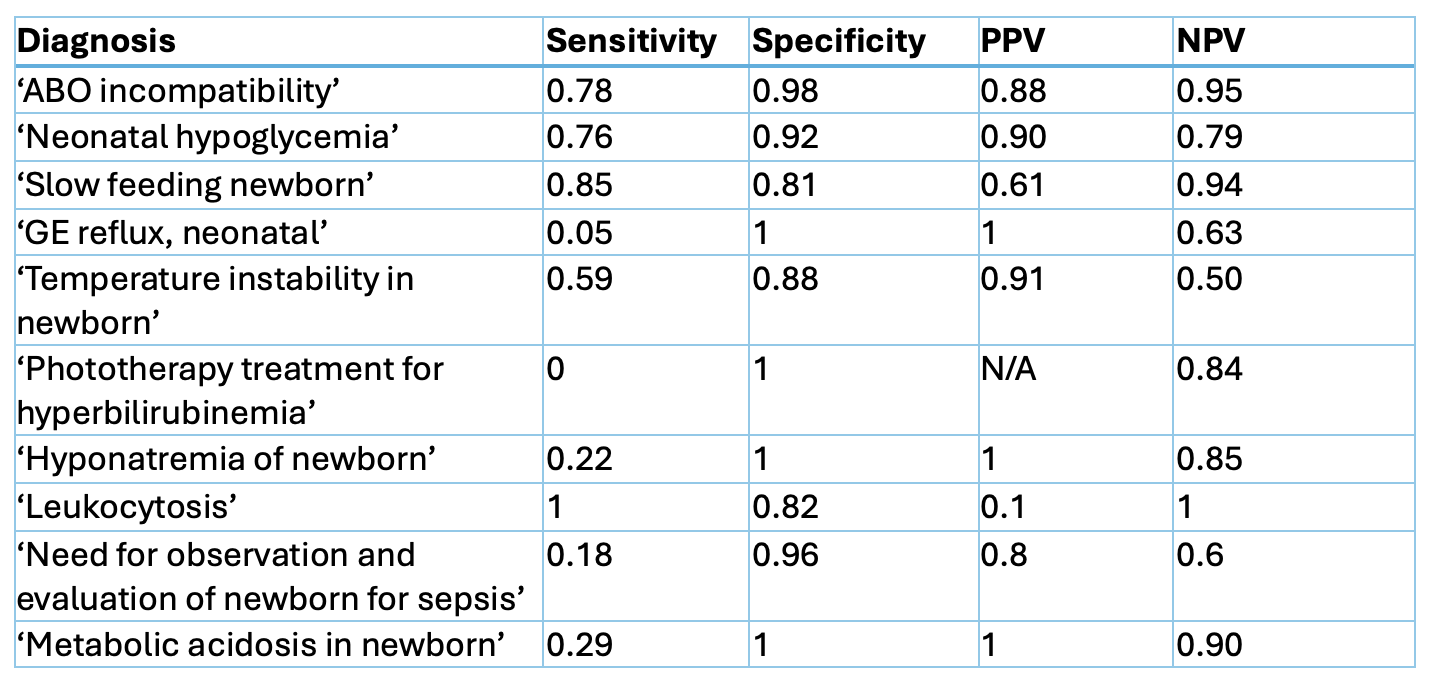 Accuracy metrics for GPT-4o by diagnosis. The following diagnoses are excluded from the table for insufficient volume in the sample: ‘Hypocalcemia and hypomagnesemia of newborn’, ‘Neonatal hypermagnesemia’
Accuracy metrics for GPT-4o by diagnosis. The following diagnoses are excluded from the table for insufficient volume in the sample: ‘Hypocalcemia and hypomagnesemia of newborn’, ‘Neonatal hypermagnesemia’ 