
Technology 1: AI/Machine Learning
Session: Technology 1: AI/Machine Learning
 photo")
Mei-Jy Jeng, MD, PhD (she/her/hers)
Professor
National Yang Ming Chiao Tung University
Taipei, Taipei, Taiwan (Republic of China)
.jpg) Table 1. Characteristics of enrolled infants receiving video recording (Table 1-1) and the percentage of correct keypoints (PCKs) for each keypoint across three models (Table 1-2).
Table 1. Characteristics of enrolled infants receiving video recording (Table 1-1) and the percentage of correct keypoints (PCKs) for each keypoint across three models (Table 1-2)..jpg) Figure 1. Overview of the algorithm’s process and the ResUnet architecture employed for infant pose estimation. (A) Settings of video recordings. (B) An example of keypoint detection, is where the captured video frames are processed to illustrate manually corrected keypoints, forming a skeletal representation (stickbaby) of the infant. (C) Representation of the array of keypoints which indicates the x and y coordinates of each keypoint across multiple frames. (D) Schematic representation of the final model architecture that incorporates these keypoints for developing a robust pose estimation framework. (E) Schematic flow description of the ResUnet architecture employed for the infant pose estimation of the present study.
Figure 1. Overview of the algorithm’s process and the ResUnet architecture employed for infant pose estimation. (A) Settings of video recordings. (B) An example of keypoint detection, is where the captured video frames are processed to illustrate manually corrected keypoints, forming a skeletal representation (stickbaby) of the infant. (C) Representation of the array of keypoints which indicates the x and y coordinates of each keypoint across multiple frames. (D) Schematic representation of the final model architecture that incorporates these keypoints for developing a robust pose estimation framework. (E) Schematic flow description of the ResUnet architecture employed for the infant pose estimation of the present study. 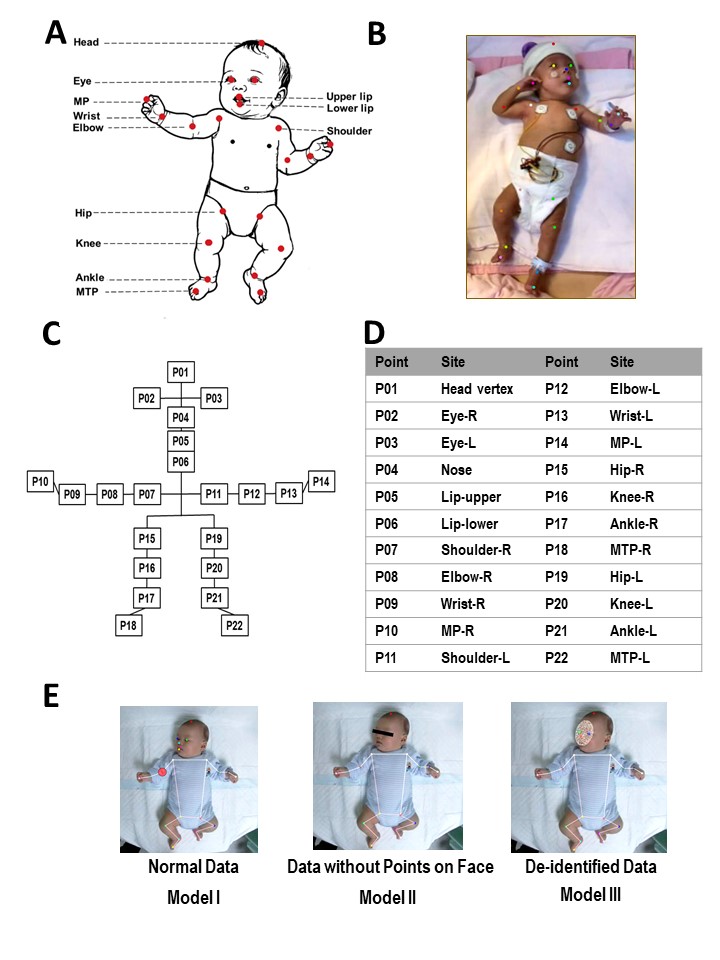 Figure 2. Overview of visualization for assessing keypoints of infants and the data collection methodology. (A) Schematic representation of the key anatomical landmarks of an infant model. (B) An example of a participant preterm infant displaying identified anatomical points using colored markers to indicate anatomical sites. (C) Diagram highlighting the relationships between anatomical points labeled P01 through P22. (D) Table listing each anatomical point (P01-P22) along with the corresponding anatomical site. Points are recorded for both right (R) and left (L) sides. (E) Demonstrations of three models: Model I, normal data with all points visible; Model II, data without face points; Model III, de-identified data.
Figure 2. Overview of visualization for assessing keypoints of infants and the data collection methodology. (A) Schematic representation of the key anatomical landmarks of an infant model. (B) An example of a participant preterm infant displaying identified anatomical points using colored markers to indicate anatomical sites. (C) Diagram highlighting the relationships between anatomical points labeled P01 through P22. (D) Table listing each anatomical point (P01-P22) along with the corresponding anatomical site. Points are recorded for both right (R) and left (L) sides. (E) Demonstrations of three models: Model I, normal data with all points visible; Model II, data without face points; Model III, de-identified data.