
Technology 1: AI/Machine Learning
Session: Technology 1: AI/Machine Learning
 photo")
Emma Albrecht, MD (she/her/hers)
PGY-2
Phoenix Children's Hospital
Phoenix, Arizona, United States
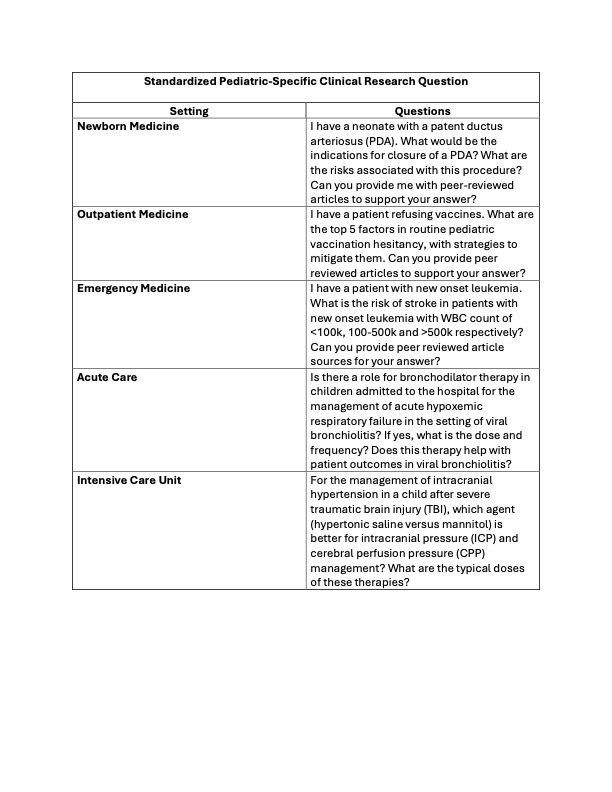 Standardized Pediatric-Specific Clinical Research Questions
Standardized Pediatric-Specific Clinical Research Questions CRAAP Scores by Modality Type
CRAAP Scores by Modality Type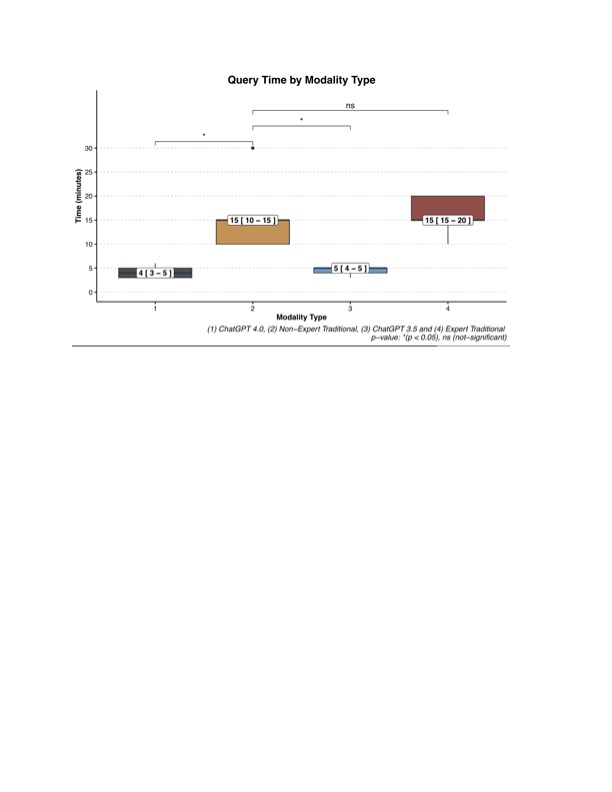 Query Time by Modality TypeStandardized Pediatric-Specific Clinical Research QuestionsCRAAP Scores by Modality TypeQuery Time by Modality Type
Query Time by Modality TypeStandardized Pediatric-Specific Clinical Research QuestionsCRAAP Scores by Modality TypeQuery Time by Modality Type