
Technology 1: AI/Machine Learning
Session: Technology 1: AI/Machine Learning
 photo")
Felix Richter, MD, PhD (he/him/his)
Hospitalist and Instructor
The Mount Sinai Kravis Children's Hospital
New York City, New York, United States
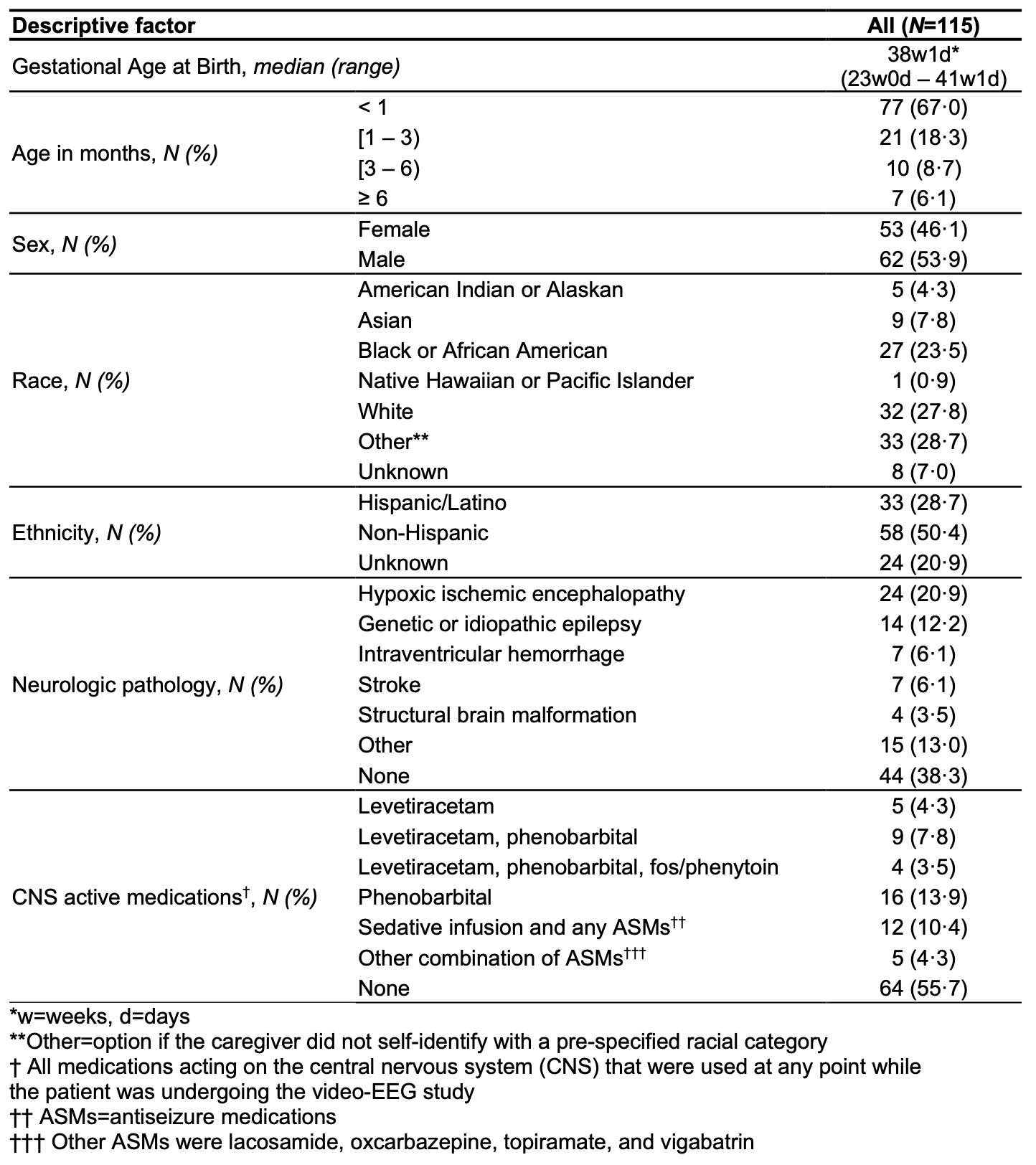
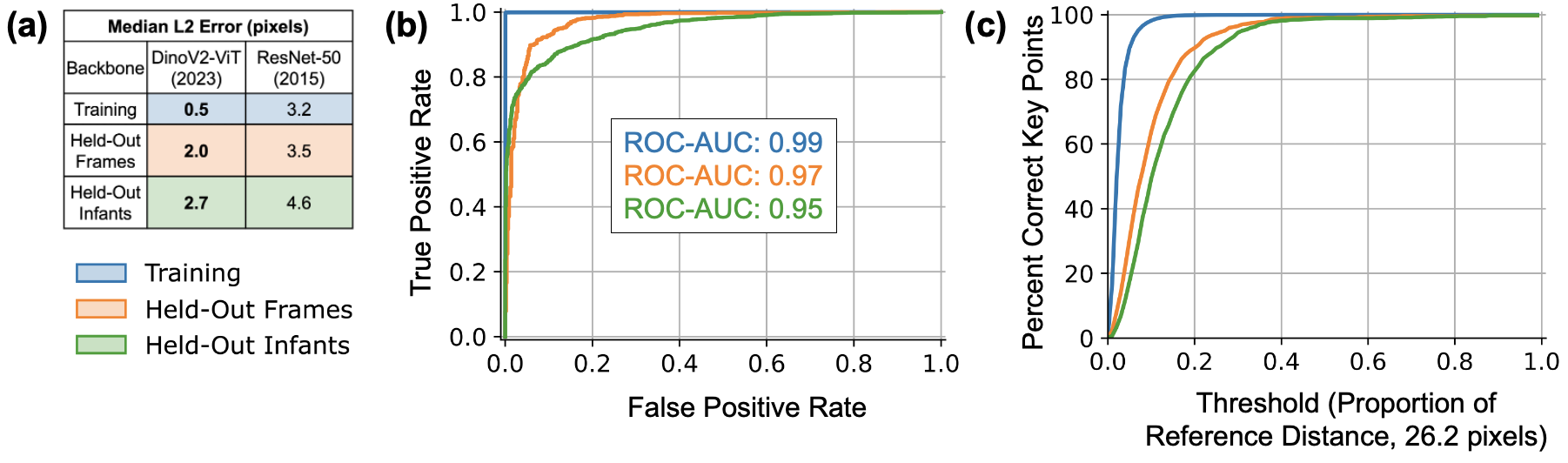 (a) Median L2 pixel error, the distance between predicted and manually labeled landmarks, in our ViT model (using DinoV2) was better than a recently published infant Pose AI model that used the decade-old ResNet backbone. (b) ROC-AUCs, a measure of ability to correctly predict anatomic landmark occlusion, were high on three evaluation datasets and higher than previously published results, which ranged 0.89–0.94. (c) The percentage of correct key points (PCK), which is the proportion of points within a reference distance threshold (26.2 pixels in our data), was >98%, comparable to state-of-the-art pose algorithms in adults.
(a) Median L2 pixel error, the distance between predicted and manually labeled landmarks, in our ViT model (using DinoV2) was better than a recently published infant Pose AI model that used the decade-old ResNet backbone. (b) ROC-AUCs, a measure of ability to correctly predict anatomic landmark occlusion, were high on three evaluation datasets and higher than previously published results, which ranged 0.89–0.94. (c) The percentage of correct key points (PCK), which is the proportion of points within a reference distance threshold (26.2 pixels in our data), was >98%, comparable to state-of-the-art pose algorithms in adults.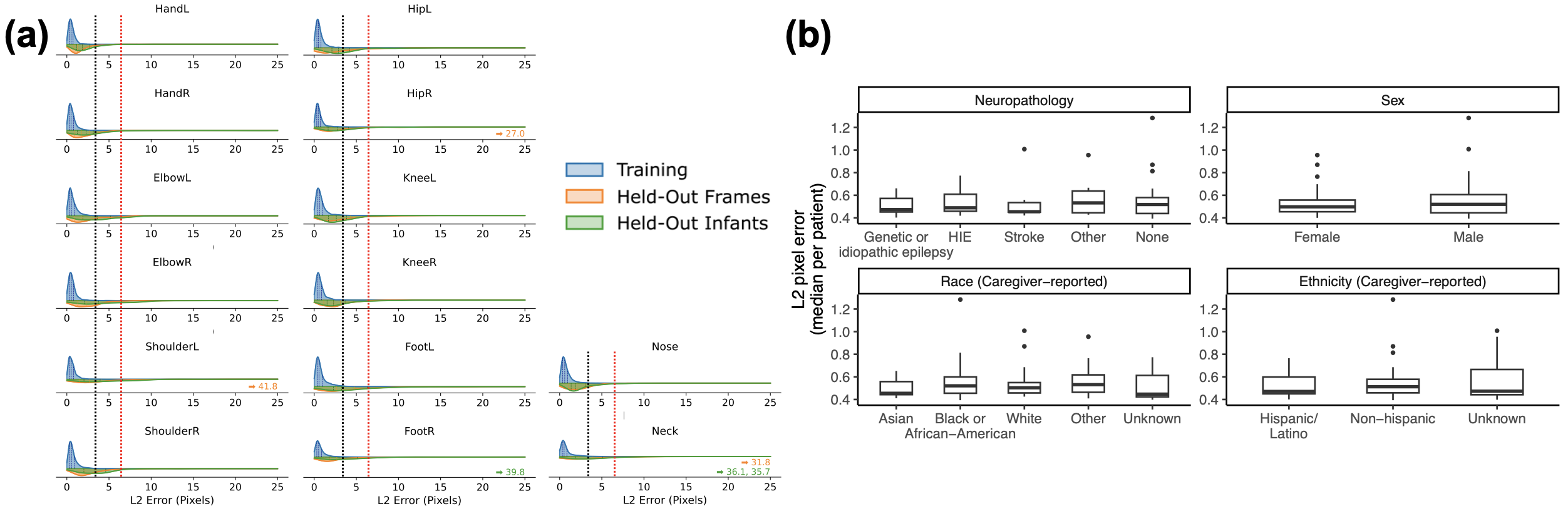 (a) L2 pixel error, the distance between predicted and manually labeled landmarks, is shown as violin plots. It was consistently low across all labeled landmarks for frames from training data (blue, median 0.54 pixels, N=22,319), frames held out from training (orange, median 2.0 pixels, N=974), and frames from infants held out from training (green, median 2.7 pixels, N=1399). The best L2 pixel error performance using the older ResNet architecture from 2015 on the same data is shown as a vertical black dashed line (3.2 pixels). Previously reported human inter-rater variability, standardized to our camera resolution, is shown as a vertical red dashed line (6.3 pixels). Six labeled landmarks (0.03%) had an extremely high L2 error (>25 pixels) and their errors are shown with arrows; this is lower than the extreme error rate with older models (0.1%, Fisher’s P=3x10^-6). (b) The L2 pixel error, shown as box plots with the median and 25th/75th quartiles, was not statistically significantly different within neurologic pathology, sex, and caregiver-reported race/ethnicity (all four Kruskal-Wallis P>0.3).
(a) L2 pixel error, the distance between predicted and manually labeled landmarks, is shown as violin plots. It was consistently low across all labeled landmarks for frames from training data (blue, median 0.54 pixels, N=22,319), frames held out from training (orange, median 2.0 pixels, N=974), and frames from infants held out from training (green, median 2.7 pixels, N=1399). The best L2 pixel error performance using the older ResNet architecture from 2015 on the same data is shown as a vertical black dashed line (3.2 pixels). Previously reported human inter-rater variability, standardized to our camera resolution, is shown as a vertical red dashed line (6.3 pixels). Six labeled landmarks (0.03%) had an extremely high L2 error (>25 pixels) and their errors are shown with arrows; this is lower than the extreme error rate with older models (0.1%, Fisher’s P=3x10^-6). (b) The L2 pixel error, shown as box plots with the median and 25th/75th quartiles, was not statistically significantly different within neurologic pathology, sex, and caregiver-reported race/ethnicity (all four Kruskal-Wallis P>0.3).