
Critical Care 3
Session: Critical Care 3
 photo")
Nga Tang, MD (she/her/hers)
Pediatric Intensivist
Loma Linda University Children's Hospital
SAN ANTONIO, Texas, United States
.png) Our model's confusion matrix. Sensitivity of 0.71. True positive rate of 0.71. False negative rate of 0.28.
Our model's confusion matrix. Sensitivity of 0.71. True positive rate of 0.71. False negative rate of 0.28.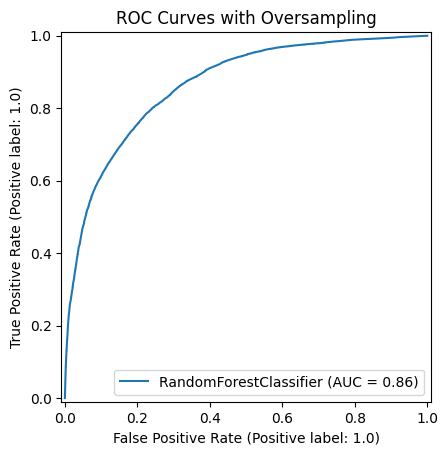 Our model's ROC Curve with oversampling, AUROC of 0.86.
Our model's ROC Curve with oversampling, AUROC of 0.86.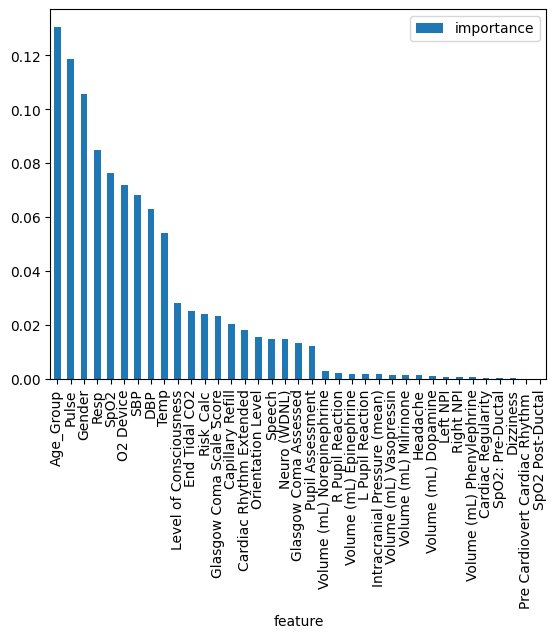 This shows which of the input features has the most impact on our model's predictions.
This shows which of the input features has the most impact on our model's predictions.